Introduction
This post aims to give information our team is currently dealing with – a investment approach used by hedge funds and proffesional portfolio managers. There are such investment approaches that do not require crystal balls to expose investment opportunities, but which are base on statistics, economic operators, logical relationships and the professional use of state-of-the-art technologies. A key fact is that there is no use of the prediction of future values for estimating the future direction of the asset analysed, but the approach seeks anomaly (market opportunities) in the relationships of different asset prices among which there is a certain (economic, political, commercial, technical) logical relationship. The result is a investment strategy which does not estimate the direction of the future development of the asset but which is able to identify the business opportunity created in real time.
Motivation
Our goal is to create/find alpha factor that gives an investor an advantage over a normal approach where an investor buys and holds a security until its maturity or sale. One source of this alpha factor is „Relative Value Trading“, which contains many investment approaches, including Statistical Arbitrage, Convertible Arbitrage, Fixed Income Arbitrage, Equity Market Neutral, Spread Trading, Pair Trading. The point of this approach is to track the logical links among the selected assets (we used 30 randomly selected U.S. shares) and the trading of anomalies that appear over time on those relationships.
Data
A wide range of underlying assets (shares, commodity futures, bonds, government bonds and CDS, convertible bonds and their underlying shares) can be used to analyse the Relative Value.
For our initial analysis, we used 30 randomly selected U.S. shares, which are currently mainly used to compile and verify the correctness of the methodology and operating process.
Once the operating process has been detuned, we will also deploy the application to other data sources.
Methodology
The Relative Value Approach is a mean-reverting investment approach where the underlying premise is a stable relationship between two or more assets.
This relationship is identified by a long-term correlation matrix of differentiations of logarithmic price of the assets entering the analysis.
These short-term anomalies provide an alpha factor on which to build a investment strategy used by proffesional portfolio managers.
Table 1: Correlation matrix of significant relationships
|
XOM |
JPM |
GS |
CVX |
| XOM |
1.000000 |
0.464594 |
0.490233 |
0.879080 |
| JPM |
0.464594 |
1.000000 |
0.733680 |
0.489734 |
| GS |
0.490233 |
0.733680 |
1.000000 |
0.523985 |
| CVX |
0.879080 |
0.489734 |
0.523985 |
1.000000 |
Figure 1: Correlation coeficients heatmap

The chart above illustrate the results of the first step. Of the 30 titles analysed, we identified 2 bilateral long-term relationships formed by JPMorgan Chase & Co. (JPM) with Goldman Sachs Group Inc (GS) and Exxon Mobil Corporation (XOM) with Chevron Corporation (CVX).
In the second step, we culled a short-term sliding correlation with a period of 10 business day, for these two relationships. The goal was to trace short-term deviations from long-term normal which will be further used as a alpha signals for a investment strategy. The results are shown in the charts bellow.
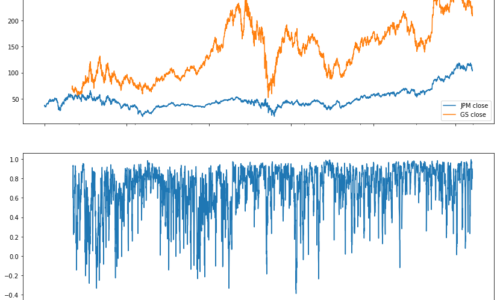
Figure 2: Comovements and short-term disruption in relationship „XOM-CVX“

Figure 3: Comovements and short-term disruption in relationship „JPM-GS“

On both lower charts you can see short-term decreases in correlation coeficients, which we consider to be signs of short-term deviations from long-term normal. We regard these short-term deviations as a investment opportunity, the automated use of which will our team further address.
Conclusion
This post aims to outline the idea of one of the investment approaches by hedge funds and professional portfolio managers and to show the results achieved by us. Further steps (robustness and stability checks of the long-term correlation matrix) will be analysed in other positions, which we are curently dealing with in the search for optimisation solutions in assets management in detail, including the technological processes.
Michal Dufek